在當今數字化轉型加速的背景下,企業級網絡安全與管理軟件成為眾多機構運營的基石。天擎V6.0專業版作為一款集終端安全、運維管理于一體的綜合平臺,其在許昌市場的供需情況備受本地企業關注。本文將針對“天擎V6.0專業版(含1年服務)”在許昌地區的市場定價與廠家報價進行梳理分析,并探討其相關的網絡服務價值。
一、產品核心價值與服務體系
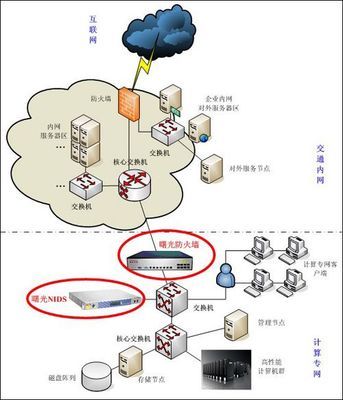
天擎V6.0專業版通常包含病毒防護、漏洞修復、終端管控、數據安全及運維審計等核心模塊。其“含1年服務”的套餐,意味著用戶在購買軟件授權的獲得了為期一年的官方技術支持、定期病毒庫更新、功能升級服務以及緊急事件響應。這部分服務是確保軟件持續有效運行的關鍵,其價值在總價中占有相當比重。
二、市場價與廠家報價的影響因素
在許昌地區,該產品的市場零售價(市場價)與直接從廠商或總代理獲得的報價(廠家報價)通常會存在差異。這種差異主要受以下因素影響:
- 渠道層級:產品通過多層經銷商(如省代、市代)到達最終用戶,每層都會增加合理的利潤空間,使得市場價往往高于廠家直銷或官方旗艦店的直接報價。
- 采購規模:單一授權采購與批量采購(例如企業一次性購買數十上百點)的單價差異顯著。廠家對于大客戶通常會有更優惠的協議價。
- 服務附加內容:雖然都標明“含1年服務”,但不同渠道商可能捆綁不同的本地化實施、培訓等增值服務,這也會影響最終報價。
- 市場競爭與促銷:許昌本地IT服務商之間的競爭,以及廠家在全國性或區域性促銷活動期間的調價,都會導致市場價的短期波動。
三、當前市場行情概覽(請注意時效性)
需要明確指出的是,軟件產品的具體價格屬于商業動態信息,且受廠商價格政策嚴格管控,通常不會公開透明地列出精確數字。根據對許昌IT采購市場的一般調研,可以了解到以下情況:
- 廠家直接報價:通常較為穩定,是市場價的基準。天擎V6.0專業版(含1年服務)的廠家官方報價(通常針對單點或標準套餐)會公布在官方渠道或向經過認證的合作伙伴提供。潛在用戶通過官方400電話或咨詢認證代理商可獲得接近廠家層面的報價。
- 許昌本地市場價:本地系統集成商或軟件銷售商的報價,會在廠家報價基礎上上浮一定比例,比例取決于上述渠道因素。這部分價格需要用戶與本地多家服務商進行詢價、比對來獲得。
四、網絡服務的核心考量
購買此類產品,不僅是購買軟件本身,更是購買其背后的“網絡服務”。這包括:
- 本地化服務能力:許昌本地的授權服務商是否能提供快速的上門安裝、調試、培訓及應急響應服務。
- 持續的技術支持:一年服務期內,能否通過電話、在線工單等方式獲得高效的技術問題解答。
- 合規與更新保障:確保病毒庫和特征庫的實時更新,以應對不斷變化的網絡威脅,滿足網絡安全等級保護等合規要求。
五、給許昌地區企業的建議
- 明確需求:首先評估自身需要的終端點數、功能模塊(是否需要全部專業版功能),避免資源浪費或功能不足。
- 官方渠道詢價:直接聯系天擎官方或其在河南省/許昌市的授權核心合作伙伴,獲取最基準的廠家層面報價與政策。
- 對比本地服務商:獲取2-3家許昌本地有授權資質的服務商的詳細報價方案,重點比較其給出的“市場價”中包含的額外本地服務內容、響應時間等,而不僅僅是總價。
- 關注服務合同:在合同中明確寫明所購產品版本、服務期限(起止日期)、服務內容、響應標準及續費條款,以保障自身權益。
****:對于許昌地區用戶而言,天擎V6.0專業版(含1年服務)的具體價格需要通過與官方及本地服務商的直接溝通來確定。在決策時,應將“網絡服務”的質量與可持續性置于與產品價格同等重要的地位,選擇最具性價比且服務可靠的授權合作伙伴,才能最大化該安全解決方案的投資回報。